
Kimball vs Inman
Authors: Yoav Shimonovich – BI solution expert
Overview
Data warehouse architecture is a broad and important concept that shapes the data structure of one’s organization. It greatly affects an organization’s data-related aspects such as data flow process, development and maintenance costs, reporting ability, etcetera. in this article, we will discuss two of the most common approaches for data warehouse architecture – the Kimball and Inman methods.
The Kimball method
Ralph Kimball (born in 1944) is one of the original pioneers of data warehousing design.
At the heart of his method stands the concept that a database must be designed to be understood and operate fast. His approach is a Business-like approach, which first takes into consideration the specific business requirements of an organization and builds the data warehouse on top of them. For example, an organization can have multiple data sources on its operational system (OLTP), but only the necessary ones will be transferred into the data warehouse, after being cleaned by an ETL process. There, it would be stored in a relational data model made from facts and dimension tables.
The following illustration shows the data flow process of the Kimball method:
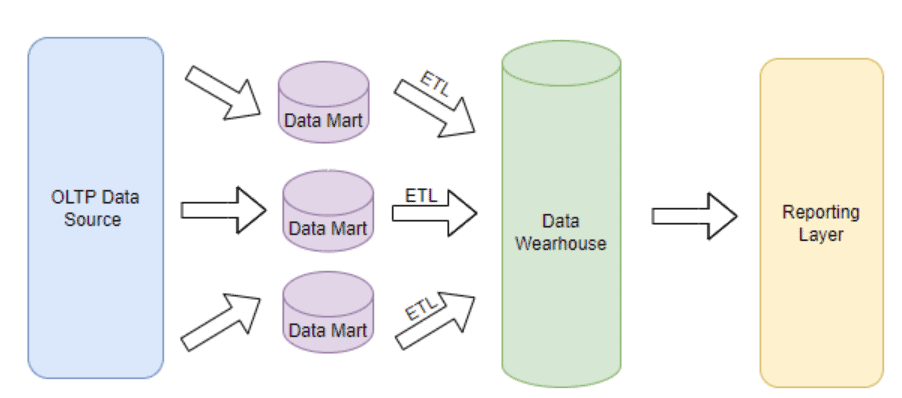
The Inman Method
Bill Inman (born in 1945) is recognized by many as the “Father of data warehousing”. his approach is considered a Technical Approach and is the opposite approach of Kimball.
From Inman’s point of view, it’s essential to first transfer all the data from the operating system (OLTP) into the data warehouse to serve as a single source of truth for one’s organization, storing it in highly normalized data model. Only then, the relevant data will be transferred into one or more data marts, according to the organization’s requirements.
The following illustration shows the data flow process of the Inman method:
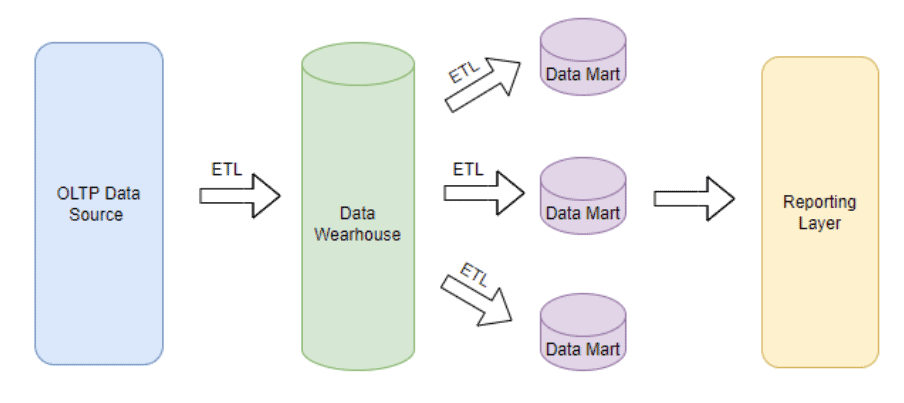
The next table summarizes the main differences between the two methods:
| Method | Kimball | Inman |
| Set-up | Relatively fast because only partial parts of the data are being transferred to the data warehouse | Relatively slow because all the company data has to be transferred to the data warehouse |
| Performance | Relatively fast due to the data being split into fact and dimension tables in a de-normalized way | Relatively slow due to the highly normalized structure of the data model |
| Data modeling complexity | Star or snowflake schemas which are considered user-friendly models to understand | The data model can become over-complex over time as more tables are joined together. |
| Costs | Relatively low because only partial parts of the organization’s data are being transferred | Relatively high due to the transfer and storage of the organization’s entire data |
| Reporting ability | Because not all the data is transferred, it can sometimes lead to difficulties for the organization’s different reporting needs | Any reporting need of the organization is being covered. |
The conclusion
Both the Inman and Kimball methods can be applied for different scenarios, and each method has its own advantages and disadvantages. To this day, the most common DWH structure uses the Kimball method due to the fact that it’s a Business-minded approach rather than a Technical approach. It is essentially much cheaper and delivers faster results with better ROI.
What is your approach?
Click here to read the previous article about the count function different use cases.



